利用芯片到芯片的光学互连来释放人工智能的全部潜力
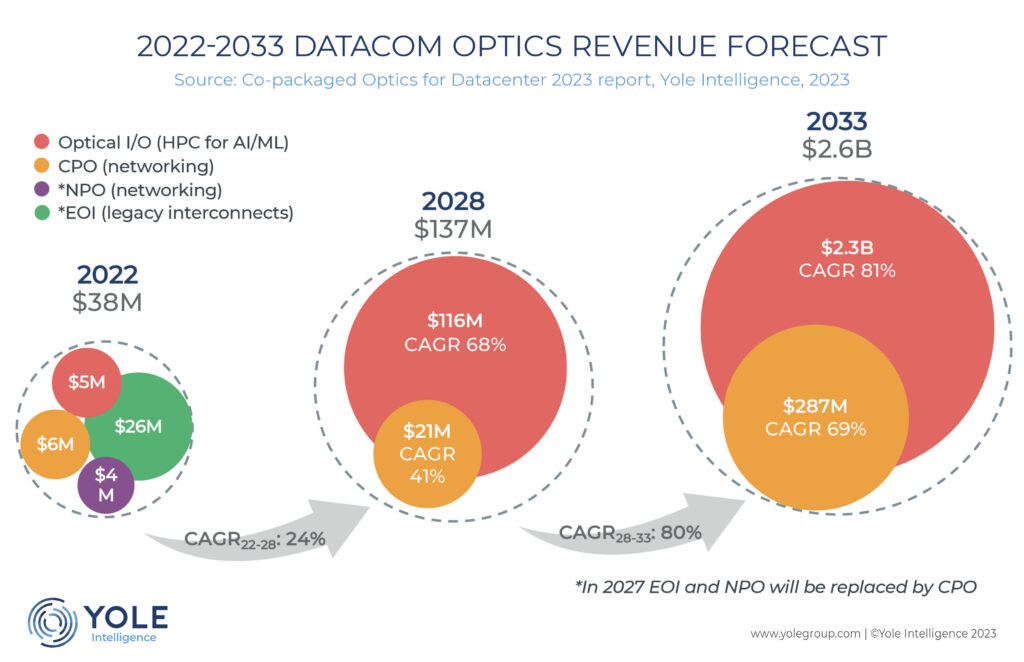
共封装光学器件(CPO)由于其在数据中心的电源效率,最近获得了关注。虽然大多数针对网络应用的CPO的主要支持者,由于宏观经济的阻力而停止了CPO计划,但用于人工智能(AI)和机器学习(ML)系统的CPO的情况却有所不同。人工智能模型对计算能力、存储和数据移动有着永不满足的需求,而传统架构正在成为扩展ML的主要瓶颈。因此,为HPC和新的分布式系统架构,出现了新的光学互连。Yole集团旗下的Yole Intelligence在其新报告《数据中心的共封装光学技术》中对此进行了回顾。用于xPU、内存和存储的封装内光学I/O技术可以帮助实现必要的带宽。此外,未来数十亿个光互连的潜力正在推动大型代工厂为设计公司的任何PIC架构的大规模生产(包括硅光子学工艺流程)做准备。2022年CPO收入约为3800万美元,预计2033年将达到26亿美元,2022-2033年年均复合增长率为46%,受AI/ML装备中数据加速传输的推动。
AyarLabs的TeraPHY?光学I/O芯片和SuperNova?光源的结合,以更低的延迟、更远的距离和现有电气I/O解决方案的一小部分功率,大幅提高带宽。其封装内部的光学I/O解决方案正在颠覆半导体和计算行业的传统性能、成本和效率曲线。Yole Intelligence的高级分析师Martin Vallo有幸采访了Ayar实验室商业运营副总裁Terry Thorn,讨论了数据中心应用的光互连的当前趋势。
Martin Vallo: 我们的最后一次采访是在2021年,当时你介绍了你的突破性光学I/O解决方案,实现了计算芯片之间的光通信。现在你们有什么新情况?
Terry Thorn: 在过去的18个月里,我们启动了几个备受瞩目的战略伙伴关系,同时也与大批量的代工厂、激光器和供应链合作伙伴建立了关键关系。2022年开始,我们庆祝了与惠普企业的战略合作。此后不久,Global Foundries宣布了其新的Fotonix制造工艺,我们在2021年6月的OFC2022上用它来展示了我们的第一个工作硅。
其他重要的里程碑包括我们1.3亿美元的C轮融资,以及与GPU和人工智能强手英伟达和领先的航空航天和国防承包商洛克希德-马丁公司合作开发光互连。在2022年结束时,我们与美国国防部签订了1500万美元的多年期项目KANAGAWA,该项目将促进Ayar Labs光学互连的下一步发展,引领其过渡到国防部的先进封装生态系统。
最近,我们举行了一次光学I/O解决方案的现场演示,成功展示了每秒4兆比特(双向)的数据传输。我们还在生态系统合作伙伴的展位上展示了我们的技术,包括Global Foundries、Quantifi Photonics和Sivers Photonics。在今年的OFC上,我们在封装边缘与英特尔的可拆卸光学连接器的解决方案原型的揭幕,也引起了很多人的兴趣。在传统的边缘耦合方法中,光纤带是用环氧树脂永久地连接到V型槽中的。可拆卸式光连接器提供了一种更换光纤带的方法。仍在开发中的可拆卸式光连接器有希望获得更高的封装产量和易于现场更换。
我们还看到,使用芯片粒(chiplets)的趋势越来越强,并有强大的标准化努力来实现一个开放的芯片生态系统。这是一个重要的发展,与我们以芯片粒形式提供光学I/O解决方案的愿景是一致的。

Ayar Labs的TeraPHY?光学I/O芯片具有4 Tbps的双向带宽,低于5pJ/b,每个芯片粒+TOF的延迟为5ns,覆盖范围从毫米到公里。由Ayar Labs提供,2023年。
Martin Vallo:我们观察到人们对CPO的兴趣减少了,特别是对交换机的应用。然而,高性能计算对光I/O的需求仍在继续。这其中的根本原因是什么?
Terry Thorn:光I/O更适合于高性能计算(HPC)和人工智能(AI)/机器学习(ML)应用,在这些应用中,你需要分布式计算和共享内存容量,以满足对性能、功率和带宽的要求,同时不增加延迟。采用波分复用(WDM)和简单调制的光I/O所需的功率要小得多,并允许更大的密度:低至几pJ/bit,带宽密度高达1 Tbps/mm,导致仅有几纳秒的延迟,而CPO往往使用复杂的调制方案,则需要数百纳秒。
此外,作为一个电光收发器,光I/O使用一个微镜调制器结构,需要更小的芯片面积,从而降低了成本。例如,我们的微镜调制器的尺寸大约是Mach-Zehnder调制器的百分之一。最后,光输入/输出采用波分复用技术,允许将多个数据流装入一根光纤,以实现非常高的吞吐量。
Martin Vallo:光学I/O的第一个实际应用将是什么,我们什么时候可以期待一个公告?在我们看到AI/ML系统中的第一个光I/O之前,有哪些挑战需要克服?
Terry Thorn:我们看到许多不同的应用都遇到了同样的功率、性能和延迟挑战,而每一种应用都对光I/O有强烈的需求:
人工智能和HPC:AI/ML和HPC应用需要一个分布式的加速器网络来分散计算和共享内存容量。在内存容量方面,一个拥有数千亿个参数的AI/ML模型可能需要高达2TB的内存容量来存储中间计算结果。当你在一个集群中连接数百个GPU,使每个GPU都能与其他GPU对话时,每个GPU所需的数据吞吐量会迅速增加。这给带宽密度带来了巨大的压力,这是衡量每个封装边缘或区域所能实现的数据吞吐量。光学I/O对于实现所需的带宽密度、功率和延迟性能指标以实现更大的集群是至关重要的。
高带宽内存(HBM)扩展器:一个GPU通常被两到四个本地内存HBM堆栈所包围,每个都有大约64GBytes的内存容量。对于HPC和AI/ML应用,这个容量是不够的。HBM内存扩展器可用于增加内存容量至数百GB字节或更多。由于内存应用对延迟非常敏感,使用光学I/O链路来连接GPU和扩展器内存模块是必要的。仅仅由于延迟问题,可插拔光学器件或CPO光学器件是不适合的。
内存池和可组合的基础设施:随着云计算基础设施处理动态变化的工作负载,灵活的汇集和共享内存的功能正变得至关重要。愿景是将基于工作负载的集群与所需的CPU、GPU、内存和存储资源组合在一起,实现高性能和低延迟。随着CXL?标准的采用,光学I/O互连正在成为关注点。
用于航空航天和国防的传感系统:在这个方面,反映了我们最近宣布与洛克希德-马丁公司的战略合作,光学I/O被用来捕获、数字化、传输和处理光谱信息。将高密度、高效率的光学I/O芯片粒,与射频处理设备置于同一封装中的多芯片封装解决方案将被用于相控阵孔径,以连接系统,做出更智能、更快速的决策。
目前,光学I/O的主要挑战是生态系统的发展,这需要许多公司的协调。我们正在与广泛的合作伙伴合作,促进该生态系统的发展。至于这些应用的首次公布,考虑到现有的市场需求,我们预计这些应用会来得更早而不是更晚,也许在未来一年左右。

Ayar Labs的TeraPHY?光学I/O晶圆来自Global Foundries Fotonix?单片RF-CMOS平台。由Ayar实验室提供,2023年。
Martin Vallo:光学I/O性能使xPU能够在从毫米到两公里的广泛距离内相互通信。因此,预计AOC(以太网)和光学I/O(CXL、UCIe)之间会有激烈的竞争。这两种技术之间的斗争将如何进行?
Terry Thorn:以太网应用和以计算或内存为中心的应用之间有明显的区别,所以我们不认为AOC是一个直接的竞争对手。在以计算或内存为中心的互连协议中,Compute Express Link?(CXL)和Universal Chiplet Interconnect Express?(UCle?)是互补的。CXL是一个较高层次的协议,传统上在PCIe物理层上运行。最近,CXL已被扩展到也可与UCIe物理层一起工作。对于机架内或跨机架的片外连接,使用光I/O技术构建的UCIe光复接器可以提供AOC无法满足的低功耗、低延迟和高带宽密度指标。
通过光互连,我们可以用更低的功耗和延迟实现更大的范围。仍然会有一些对延迟不敏感的应用可以满足更高的功率要求,而以太网将是首选,包括系统与系统之间的通信。在这些情况下,可以使用AOC。但是一旦你开始考虑深度学习和HPC应用, 同样,你要把许多计算节点连接在一起的话,AOC可能无法满足所有的性能指标。
Martin Vallo:你如何看待光学I/O在技术方面的发展?
Terry Thorn:首先,光学I/O具有高度的可扩展性,该技术将有几种发展方式。一个是每根光纤的lambdas数量。我们目前使用的是每根光纤8个lambdas,但CW-WDM MSA(连续波分复用多源协议)路线图已经有每根光纤16和32个lambdas的规范。每当你把每根光纤的lambdas数量增加一倍(保持其他方面不变)就会自动把带宽增加一倍。我们还可以扩大光端口的数量(我们目前使用的是8个)并提高调制率(我们目前使用的是32Gbps的调制率)。
在光I/O内部,我们预计将看到在使用内部或外部激光器方面的不同意见。考虑到紧凑的外形尺寸、灵活性和现场可更换性,我们仍然倾向于外部激光器的方法。我们还认为UCIe是最适合于芯片到芯片连接的标准,它促进了实施光学I/O的芯片方法。

一个包含四个Ayar Labs TeraPHY?光学I/O芯片和一个客户ASIC的多芯片封装。由Ayar实验室提供,2023年。
Martin Vallo:围绕激光源的关键规格是什么?我们是否会在未来看到光学芯片中广泛集成激光器?
Terry Thorn:目前业界的趋势是使用外部激光源,我们相信这种趋势会持续下去。在光学I/O中,激光器是最敏感的部件,需要在较低的温度环境下工作。把它放在外部,与计算硅分离,可以更好更有效地控制温度。如果你把激光器模块放在计算硅旁边,来自计算节点内的GPU和CPU的热量会影响激光器的性能。
我们确实希望看到梳状激光器的使用,但它们仍处于早期研究发展阶段。当该技术成为商业化的时候,我们可以看看这个东西。但是,最终,我们相信保持 "外部激光不可控 "在制造和部署方面是最合理的。
Martin Vallo:有很多关于分布式机架架构的讨论,目前是光学I/O技术的主要驱动力。你能分享一下这会如何发展吗?
Terry Thorn: 分散的基础设施需要光I/O来扩展到机架级别甚至更高的级别。将内存与处理器和加速器解耦的分布式机架可以实现更灵活、更经济的节点设计,满足下一代HPC和AI工作负载的需求。为了使分布式机架成为可能,一个能够在几米到几百米的距离内以低功率和低延迟提供高吞吐量的互连是至关重要的。CXL是一种新兴的用于分布式机架的统一协议,使用PCIe电信号进行I/O互连,其覆盖范围有限。为了扩大覆盖范围和扇形范围,人们对 "CXL over optical "I/O互连有强烈的兴趣。
例如,很容易设想一种可组合性方案,其中几个CPU包含在一个机箱中,而GPU在一个单独的机箱中,而内存则占据另一个机箱。随着工作负载的扩大,你可以将两个CPU、一个GPU、几个SSD和汇集一定量的内存组成一个节点。CXL为内存分解带来了缓存一致性互连,这就是为什么这么多公司正在努力实现利用CXL的解决方案,我们相信光I/O是实现这一愿景的关键成分。
这里的另一个重要角度是分布式计算,这又回到了一个事实,即人工智能/ML和深度学习都需要大量的训练参数,现在是以万亿计。在各种计算节点之间共享计算和内存将越来越有必要。连接这些节点并有效扩展的唯一可靠方式是通过光学I/O。

四个Ayar Labs TeraPHY?光学I/O芯片和一个客户的ASIC在一个多芯片封装中。由Ayar实验室提供,2023年。
Martin Vallo:把电/光接口带到芯片旁边,将大大影响这个行业。您能否解释一下供应链将受到怎样的影响?
Terry Thorn:该行业目前正面临着显著的连接瓶颈,这迫使各参与者探索新的方法。我们看到的一个趋势是将SoC的单芯片分解成芯片粒。将电光芯片纳入封装内,紧挨着SoC核心芯片是这种趋势的延续。这种共封装的方法将会改变供应链的复杂性。
除了用芯片粒封装外,光纤连接和测试方法也需要发展。我们还看到代工厂(即Global Foundries、英特尔和最近的台积电),在支持集成电子/光学元件方面取得的巨大进展和承诺。最后,选择将激光器放在外部是我们能够减轻这些供应链复杂性的一种方式。
标准化也将在解决供应链挑战和扩大这项技术的规模方面发挥关键作用。UCIe和CXL都在寻求解决光纤互连的问题,并正在探索制定光学I/O规范。此外,CW-WDM MSA是一个重要的行业倡议,它正在定义和促进光学激光源的新标准和规范。由于光I/O是一项革命性的技术,对行业的许多领域都有影响,因此发展和培育这个完整的生态系统有巨大的需求。
Martin Vallo:光学I/O技术将如何影响其他应用?
Terry Thorn:这是个好问题。我们已经谈了很多关于HPC和AI/ML的问题,但我们也希望看到它在其他需要快速传输数据的领域的应用增长,例如在云和数据中心、电信、航空航天和国防、自动驾驶、AR/VR等。随着光学I/O的成熟和变得更具成本效益,我们看到它有可能满足广泛的应用中不断增长的带宽、功率和延迟要求。
本文地址:http://www.iccsz.com//Site/CN/News/2023/05/12/20230512084417977012.htm 转载请保留文章出处
关键字: CPO
文章标题:利用芯片到芯片的光学互连来释放人工智能的全部潜力
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- · CableLabs大力宣传100G CPON技术的进展
- · 技术文章 | 如何全面评估共封装光学组件(CPO)性能
- · 腾景科技答投资者:CPO采用新的封装和光纤耦合设计 产品用于400G、800G光模块当中
- · CIR发布最新CPO模块市场预测 预计2027年达55亿美元
- · 中际旭创2022年营收96.42亿元 高速光模块销量达618万只
- · 特发信息答投资者:与阿里巴巴有合作 MPO光纤连接器接头可适配CPO
- · 华拓光通信:对投资者关注的CPO等热点问题的答复
- · 光力科技:CPO是一种新型光电子集成技术 公司在煤矿领域与华为合作
- · 华工科技:200G AOC在测试阶段 800G FR4产品认证中
- · 亨通光电:CPO光电协同封装技术布局较早 800G光模块已通过测试但未量产
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1