Gazettabyte:Oriole的快速光重构网络
ICC讯 Oriole Networks近日荣幸地接待了Gazettabyte的Roy Rubenstein到访其伦敦办公室。Roy与公司多位高管进行了会面,深入了解了全球首个面向AI的全光网络解决方案PRISM。作为他对OFC 2025行业观察的一部分,Roy撰写了一篇精彩的访问报道——以下是该报道全文。
初创公司Oriole Networks开发出一种光子网络,用于连接人工智能数据中心内的众多加速器芯片。这种快速光子网络每100纳秒可重构一次,旨在取代多层电交换机。Oriole表示其光子网络可显著节省电力,并确保网络不再成为计算瓶颈。

Oriole Networks CTO Georgios Zervas
在伦敦一间沐浴着春日阳光的办公室里,来自Oriole Networks的团队详细阐述了他们对AI和高性能计算(HPC)数据中心的愿景。
Oriole开发了一种名为Prism的网络解决方案,该方案使用快速可重构的光路开关来替代数据中心中用于连接AI处理器机架的传统电包交换机层级。
电交换机在数据中心中起着关键作用,使由数千个加速器芯片组成的AI计算机得以扩展。这些芯片包括图形处理器(GPU)、张量处理器(TPU)或更通用的xPU,它们被用来处理大型AI计算任务。这些任务包括将学习印刻到大型AI模型上,或者在AI模型训练完成后进行推理,即在提示时分享知识。
Oriole的新网络基于光路开关,能够根据工作负载的变化迅速切换,按需分配xPU资源。虽然电交换机已经能很好地做到这一点。
技术渊源
Oriole成立于2023年,建立在Georgios Zervas及其UCL研究团队十多年的研究成果之上。该公司已筹集了3500万美元资金,其中包括由投资公司Plural的Ian Hogarth领投的2200万美元A轮融资。Ian Hogarth是一名技术企业家,也是英国AI安全研究所的主席。
目前50人的团队分布在伦敦、佩恩顿和帕洛阿尔托三地,汇聚了包括Paignton前Lumentum相干收发器团队和西伦敦前英特尔Altera部门的光子学以及针对超大规模企业需求的可编程逻辑设计专家。
AI数据中心指标
电力是限制AI数据中心生产力的关键因素之一。
Oriole副总裁Joost Verberk指出:"数据中心的电力供给有限,系统和网络必须尽可能高效,才能将电力集中供给GPU。"
Oriole提到了Nvidia的Jensen Huang在其最近GTC活动上使用的两个指标来量化AI数据中心的效率。一个是每兆瓦每秒生成的token数(tokens/s/MW)。Token是指数据元素,例如单词的一部分或图像像素条带,这些会被输入或由AI模型生成。生成的token越多,数据中心的生产力越高。第二个指标是响应速度,以每秒生成的token数(tokens/s)衡量,用于评估延迟(响应速度)。
Oriole指出这两个指标并不总是同步的,但目标是用更少的电力生产更多的token并更快地完成。
讨论token意味着数据中心的硬件用于推理。然而,Oriole强调,减少训练AI模型所需电力也是一个目标。Oriole的光网络解决方案既可用于推理也可用于训练。
展望未来,只有少数几家公司,如超大规模企业,会训练最大的AI模型。许多较小规模的AI集群将被部署并用于推理。
“到2030年,80%的AI将是推理。”Oriole首席执行官James Regan说道。
网络影响
推理本质上意味着呈现的AI任务不断变化。一个含义是,连接AI处理器的网络必须是动态的:为特定任务抓取处理器并在任务完成后释放它们。
Oriole首席技术官George Zervas指出,尽管Nvidia使用相同的GPU进行训练和推理,但Google最新的TPU Ironwood具有推理增强功能。Google还拥有专用于推理工作的AI计算集群。与此同时,AWS则使用不同的加速器芯片分别进行推理和训练。这两种处理器的互连带宽要求(输入-输出,或I/O)不同,推理处理器的要求较低。
对于训练来说,根据任务的并行化方式,处理器/xPUs之间的数据交换高度可预测。“你可以创建一系列短时存在的光学电路,以最小化集体通信时间,”Zervas说。然而,开关必须是确定性和同步的。“你不应该有[数据包]队列,”他说。
推理过程可能访问许多AI“专家混合”模型,因此需要一个更加动态的系统。“不同的token将前往分布在xPUs上的不同专家集,”Zervas说。“有时,一些xPUs会对查询进行批处理然后一次性发送出去。”
结果是非确定性流量,这与传统云数据中心的流量模式更为接近。在这里,网络必须在几百纳秒内快速重新配置。
“我们说的是,纳米级速度的光路开关可以在任何电包交换机出现的地方发挥作用,”Zervas说。他强调即使在如此快的切换速度下,它仍然是一个电路交换机,因为两点之间有保证的路径。这不同于传统电交换机中的“尽力而为”的流量,其中数据包可能会被丢弃。
“在我们的情况下,这个链接可以持续的时间就像一个数据包一样短,”Zervas说。“我们的开关可以在每100纳秒重新配置一次。”
一旦建立了链接,数据就会被发送到另一端而不遇到排队问题。或者正如Zervas所说,这种切换匹配了数据包的粒度,但却提供了只有电路才能保证的交付。
光学在数据中心网络中的日益增长的角色
目前,诸如Infiniband或Ethernet等协议被用来连接xPU机架,通常被称为横向扩展网络。为了使xPU相互通信,通常使用包含多层电交换机的传统Clos或“胖树”架构。
由于数据中心的距离跨度较大,插拔式收发器通过网络接口卡将xPU连接到交换网络,从而连接到目标网络接口卡和xPU。
博通(Broadcom)和英伟达(Nvidia)宣布推出将光学器件与硅交换机集成的电交换机,这是一个较新的发展方向。使用这种共封装光学器件可以绕过在电交换机平台前面板上安装插拔式光收发器的需求。
谷歌(Google)也开发了自己的数据中心架构,用光路开关代替顶层的大电交换机。在这种混合网络中,电交换机仍然主导整个网络。然而,使用光层可以节省成本和电力,并允许谷歌在移动工作负载时重新配置TPU机架之间的互连。不过,谷歌的光路开关的配置速度远不如Oriole的快,肯定不是纳秒级别的。
通过其Prism架构,Oriole采取了一个激进的步骤,即替换所有的电交换机,而不是仅仅替换顶层。结果是一个平面无源光网络。(见下图)
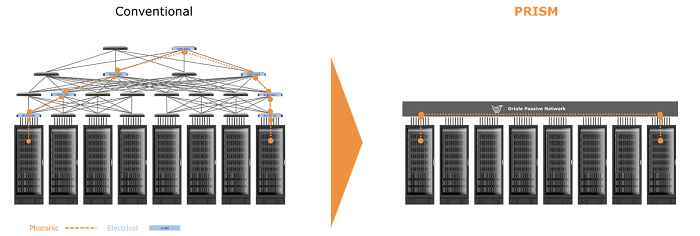
“切换发生在网络边缘,核心完全是无源的;它仅由玻璃组成,”Verberk说。由此产生的网络零数据包丢失且高度同步。消除电交换机减少了整体功耗和系统复杂性,同时提供直接的xPU到xPU高速连接。
Prism架构
Oriole的首次发布是Prism架构,该架构基于三个系统组件:
1. 基于PCIe的800G网络接口卡:集成ARM处理器的FPGA支持NVIDIA NCCL和AMD RCCL协议
2. XTR可插拔模块:集成收发与交换功能,采用可调谐激光器实现波长-空间-时间三维交换
3. 无源光子路由器:基于阵列波导光栅(AWG),零功耗实现波长路由
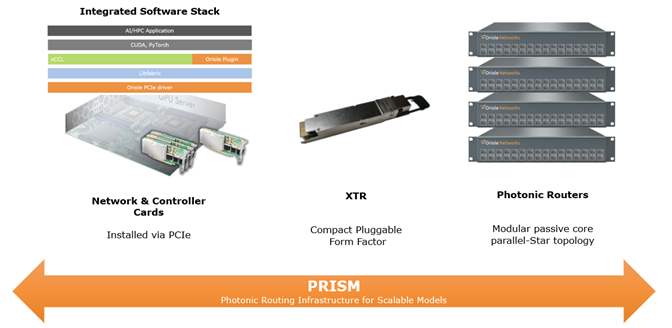
“你可以从GPU直接通过光学方式连接到另一个GPU,唯一发生的[光电]转换是在每个GPU旁边的网络接口卡上,”Verberk说。
基于PCIe的网络接口卡使用800Gbps光通信技术,并与标准软件生态系统集成。该网卡围绕一个包含ARM处理器的FPGA构建,支持通过插件实现Nvidia的NCCL(Nvidia集合通信库)和AMD的RCCL(Radeon开放计算集合通信库)等协议,确保与现有AI软件框架兼容。
该网络接口卡作为确定性数据传输设备,将用于AI计算的集合操作(例如消息传递接口操作如all-reduce、scatter-gather)映射到具有最小延迟的光路径上。
网卡的调度器将训练使用的确定性模式直接映射到波长和光纤上。同时,它根据工作负载需求动态重新配置,使用标准的直接内存访问(DMA)引擎进行推理。
XTR可插拔模块是Prism交换能力的核心。“在一个可插拔外形尺寸单元中,我们实现了传输、接收和交换,”Zervas说。
光子网络结合了三种维度的交换:光波长、空间交换和时隙(时分复用)。所选波长颜色由快速可调激光器决定。
XTR可插拔模块内的空间交换指的是所选光纤路径。“你有一束光纤,你可以选择要连接哪根光纤,”Regan说。
时间方面指的是100纳秒的时隙,即可调激光器调整到新波长所需的时间。总体而言,快速改变颜色可用于将数据路由到特定节点。
“调制通道可以决定你要连接哪个通信组或集群,光纤路径可以决定你要连接的逻辑机架,而你携带的光的颜色则可以决定机架内的节点ID,”Zervas说。
光子路由器由无源阵列波导光栅组成,构成了Prism的核心。“它们只是玻璃,这意味着它们是非热的,”Regan说,强调了其可靠性和零功耗。这些N×N阵列波导光栅根据波长和光纤选择路由光线,作用类似于棱镜。
“在一个端口,比如说输入端口,我们有红色光;如果是红色,它会到达第一个输出端,如果是蓝色,到第二个,如果是紫色,到第三个,等等,”Zervas说。
多层堆叠的多个阵列波导光栅机架可以处理大规模集群,保持单一光跳以维持一致的信噪比和插入损耗。
“每个节点与其他每个节点仅通过一次此过程,确保数千个GPU之间的一致性能,”Zervas说。
Prism的功率与计算效率
以一个包含8000个GPU的集群为例,Prism消除了128个叶交换机和64个脊交换机,减少了60%的光收发器数量。对于超过16000个GPU的更大AI集群,通常需要第三层交换。这可减少77%的收发器数量。
使用Prism不仅减少了光收发器的功耗,还通过去除电交换机及其相关冷却需求降低了整体功耗。与以太网包交换不同,Prism的光电路保证无排队的数据传输,每100纳秒重新配置一次,与数据包持续时间匹配。
在训练方面,Prism将通信开销降低至1%以下。而在现有网络中,这一数值通常为百分之几十。这意味着GPU很少等待数据,而是将时间用于处理任务。
市场与部署策略
Oriole的目标市场包括三类:金融交易企业、汽车制造商等HPC用户、交换机厂商以及超大规模服务商。
“我们的潜在客户群要广泛得多,”Regan指出,这与专注于特定芯片厂商和超大规模服务商的芯片级光I/O厂商形成对比。
Prism还包括一个以太网网关,允许其与现有数据中心集成,避免完全替换原有系统。“你可以在数据中心中需要的地方使用它,或者在新建部分使用它,”Regan说。
Oriole的路线图包括今夏的实验室演示、2026年初的Alpha硬件、2026年底的可部署产品以及2027年的量产爬坡。制造外包给高产量合同制造商。
挑战与展望
说服超大规模服务商采用非标准软件栈仍是一个障碍。“这需要合作,”Zervas指出,超大规模服务商使用专有协议。
Oriole的全栈方法——涵盖从Nvidia的CUDA库到光子电路——使其与众不同。
“你很少能遇到一家公司在[光子学和计算]两个领域都拥有深厚专业知识,”Regan说,这与只专注于光子学或计算的竞争对手形成鲜明对比。
“我们正在打造一些东西,”Regan说。“我们正在打造一个面向未来的欧洲主要网络公司,服务于AI和任意工作负载。”
原文:https://www.gazettabyte.com/home/2025/5/21/orioles-fast-optical-reconfigurable-network.html
本文地址:http://www.iccsz.com//Site/CN/News/2025/05/26/20250526023618679868.htm 转载请保留文章出处
关键字:
文章标题:Gazettabyte:Oriole的快速光重构网络
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1