用于推理和原位训练的薄膜铌酸锂中的120GOPS光子张量核心
近日,中山大学研究团队与不列颠哥伦比亚大学、女王大学、拉瓦尔大学、加拿大国家研究院、清华大学团队携手,提出了一种完全集成的光子张量核心,仅由两个薄膜铌酸锂(TFLN)调制器、一个III-V激光器和一个电荷积分光接收器组成。该光子张量核心能够以120GOPS的计算速度实现整个神经网络层,同时还允许灵活调整输入和输出的数量。相关结果以“120 GOPS Photonic tensor core in thin-film lithium niobate for inference and in situ training”为题在Nature Communications上发表。该张量核心支持快速原位训练,权重更新速度为60GHz。它通过原位训练成功地对112×112像素的图像进行了分类和聚类。此外,该团队研究人员首次在光上实现了负数与负数的乘法,为聚类AI任务的训练提供了新的方案。

文章链接:https://doi.org/10.1038/s41467-024-53261-x
光子张量核心(Photonic Tensor Core)是一种新型的并行计算核心,它利用光子进行计算,具有极高的计算速度和并行处理能力。在光子张量核心中,并行卷积处理是一种重要的计算模式,它可以极大地提高卷积神经网络的计算效率和性能。其基本原理是利用光子的高速传输特性和并行处理能力,将卷积运算分布到多个光子通道中进行,从而实现并行计算。具体来说,光子张量核心将输入数据和卷积核分别分配到不同的光子通道中,每个光子通道独立进行卷积运算,并将结果汇总起来得到最终的卷积结果。
近几年,人工智能(AI)正越来越多地被整合到各个领域,包括自动驾驶汽车、智能建筑和智能工厂,如下图1a所示。人工智能系统的核心是张量核心处理器,该核心处理器将表现出几个关键特征:首先是高速、大规模矩阵向量乘法;其次是快速更新体重,加快训练速度,促进“即时”或在线学习,这对自动驾驶汽车等应用尤其有益;最后是低能耗和紧凑的外形。
然而,找到一个同时满足所有这些要求的张量核心处理器是具有挑战性的。由于焦耳热、电磁串扰和寄生电容,传统的数字计算机难以满足矩阵代数所需的速度和能效。相比于传统的电子计算核心,光子张量核心具有更高的计算速度和更低的功耗。这是因为在光子计算中,光子的传输速度非常快,而且光子通道可以同时处理多个数据,从而实现真正的并行计算。此外,光子张量核心还可以通过复用光子通道来进一步提高计算效率和降低功耗。
尽管如此,开发一个能够进行大规模矩阵向量乘法的集成光子张量核心(IPTC),其输入和输出大小可调,同时具有快速的权重更新,仍然是一个重大挑战。
针对上述问题,该团队基于TFLN调制器在宽波长范围内工作的能力,介绍了一种集成了薄膜铌酸锂(TFLN)光子学和电荷积分光接收器的IPTC(图1b),此TFLN芯片是使用由一个360 nm厚、x切割、y传播的LN薄膜组成,该薄膜位于一个500μm厚的石英手柄上,两者之间有一个2μmSiO2层。使用光学光刻对光学器件进行图案化,并使用电感耦合等离子体进行蚀刻。然后,在光学器件的顶部沉积一层1μm厚的SiO2包覆层。然后用剥离工艺对金和加热器电极进行图案化。
这种完全集成的处理器仅包括两个TFLN调制器、一个III-V激光器和一个电荷积分光接收器。此处理器可以以高计算速度执行大规模矩阵向量乘法,如图1c所示。通过调整电荷积分光接收器的积分时间,可以灵活地修改矩阵矢量乘法的扇形尺寸。利用TFLN调制器的高调制速度和电荷积分光接收器的快速累积操作,张量核心实现了120 GOPS的计算速度。此外,该处理器的张量核心具有60 GHz的权重更新速度,可以实现快速的原位训练。
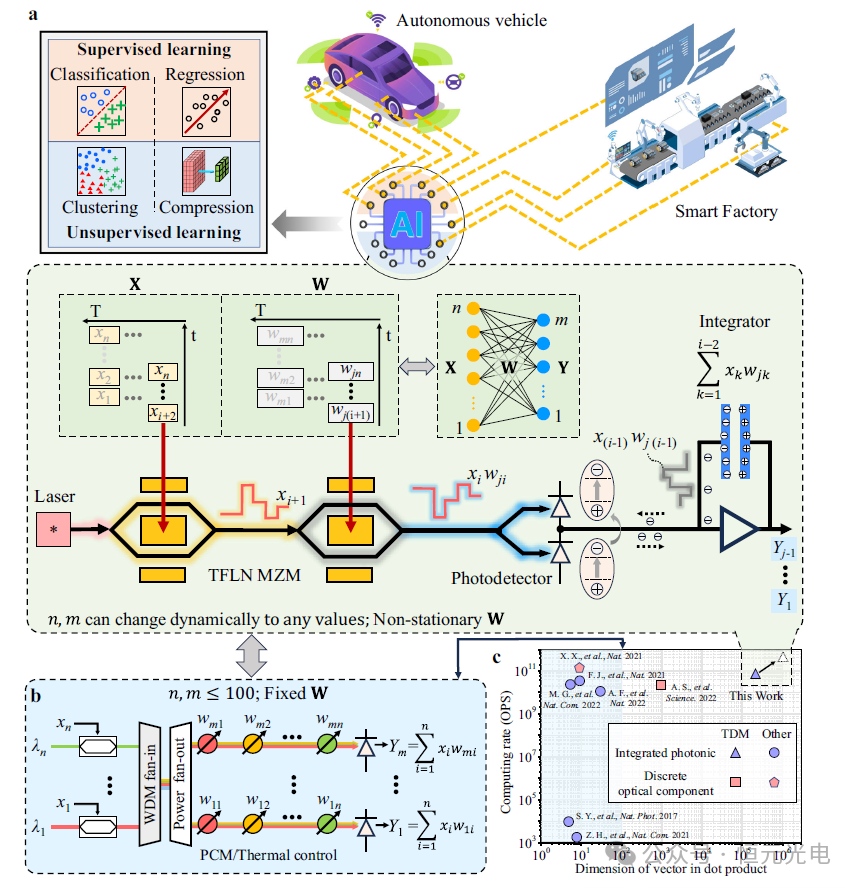
图1 集成光子张量核心(IPTC)的概念。a顶部:人工智能(AI)AI系统的应用和功能要求处理器能够适应各种AI任务,底部:IPTC的示意图。b基于传统波分复用(WDM)的IPTC的示意图。c设备的性能与几种最先进的光子张量核心的性能的比较
图2a显示了该设备的原型照片。此外,图2b–e分别提供了所制造的TFLN芯片、倒装芯片光电探测器、调制器行波电极和激光器的放大显微照片。该团队使用倒装芯片键合技术,在平衡检测方案中,将两个光电探测器(标记为PD1和PD2)固定在两个光栅耦合器上方,如图2c所示。激光器和TFLN芯片使用光子引线键合连接,其形状可以调整以匹配波导刻面的实际位置(见图2e)。如图2c右侧所示,该研究团队还通过光子引线键合将TFLN芯片与光纤阵列连接,用于校准偏置电压和延迟时间,并协助涉及两个负数的乘法。图2f显示了TFLN芯片、激光器和光电探测器的相对高度。
图2g显示了从波长为1307.22 nm的激光器耦合到TFLN芯片的光的光电流-电压(L-I-V)曲线。由于周期性电容加载行波电极(见图2d),因此,该团队所使用调制器的3-dB电光带宽比60 GHz更宽(见图2h)。对于恒定的输入光功率,积分器的输出电压随积分时间线性增加(见图2i)。在平衡检测方案中,当PD1接收到的光功率低于PD2接收到的功率时,积分器的输出电压变化为正,当它高于PD2接收的光功率时,集成商的输出电压波动为负。这意味着所提出的光接收器可以在矩阵向量乘法中执行加法和减法运算。
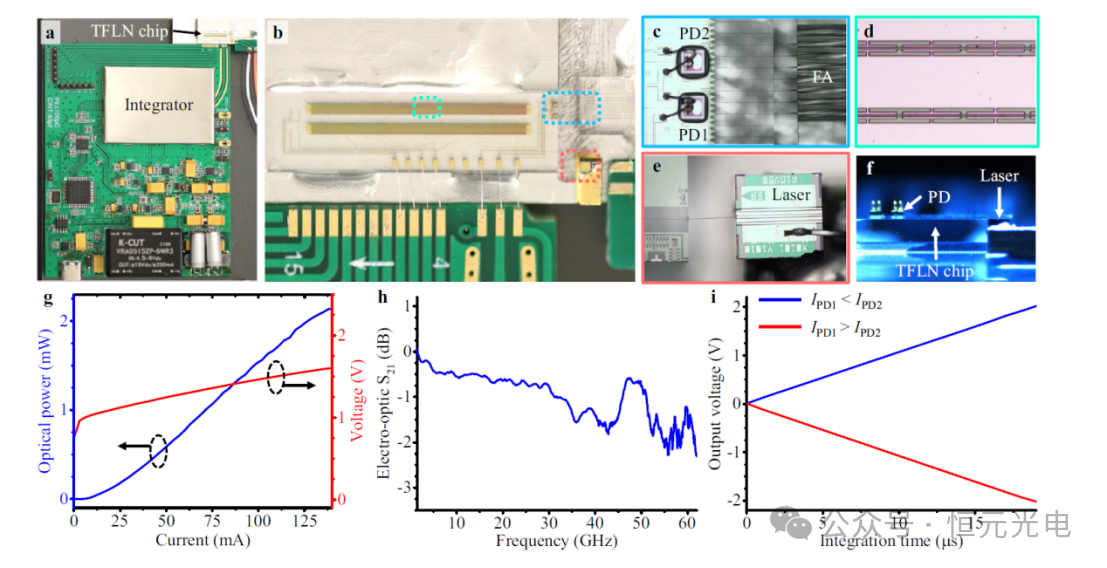
图2 封装设备的原型。a整个设备的照片。b混合集成芯片的显微照片。c–e分别是倒装芯片光电探测器(PD)、调制器行波电极和激光器的放大显微照片。f设备侧视显微照片。g从激光器耦合到TFLN芯片中的光的光电流-电压曲线。h调制器的电光带宽(S21参数)。i当输入光功率固定在一定值时,光接收器的输出电压随积分时间而变化。
该研究团队通过利用Python控制所有的设备,在两个向量之间执行点积运算,图3a显示了通过设备的数据流示意图。通过随机改变两个矢量,使用设备记录了3780个光子点积测量值。每个矢量的维度设置为131072,这两个矢量分别由两个调制器以60 GB的调制率进行调制,从而实现了120 GOPS的计算速度和60 GHz的权重更新速度。最初校准了两个向量之间的时间延迟,以确保第一个向量的每个元素都能正确地乘以第二个向量的对应元素。测量的输出电压(即点积结果)在-1和+1之间缩放,作为预期点积结果的函数,如图3b所示。与预期的点积结果相比,测量结果的误差标准偏差为0.03(6.04位),超过了执行AI任务所需的4位精度。
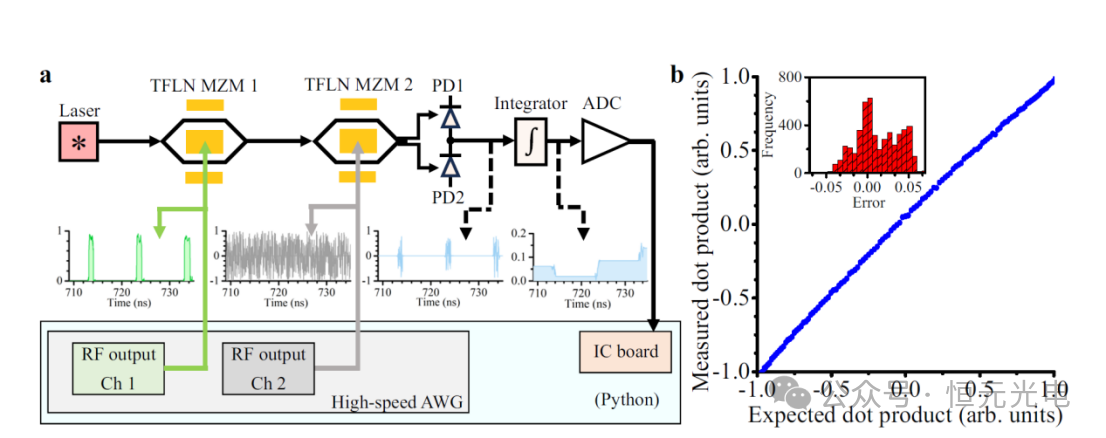
图3 使用设备进行点积操作的实验结果。a设备工作原理示意图。b设备以120GOPS的计算速度在两个131072维向量之间执行点积运算的结果。
图像分类
该团队构建了一个多层感知器(见图4a),并在大规模手写数字数据库上对其进行了测试。每个手写数字图像有112×112像素,被展平成12544×1的向量作为第一层的输入。第一和第二隐藏层中的节点数量分别设置为70和300,并且泄漏ReLU函数用于非线性激活函数。
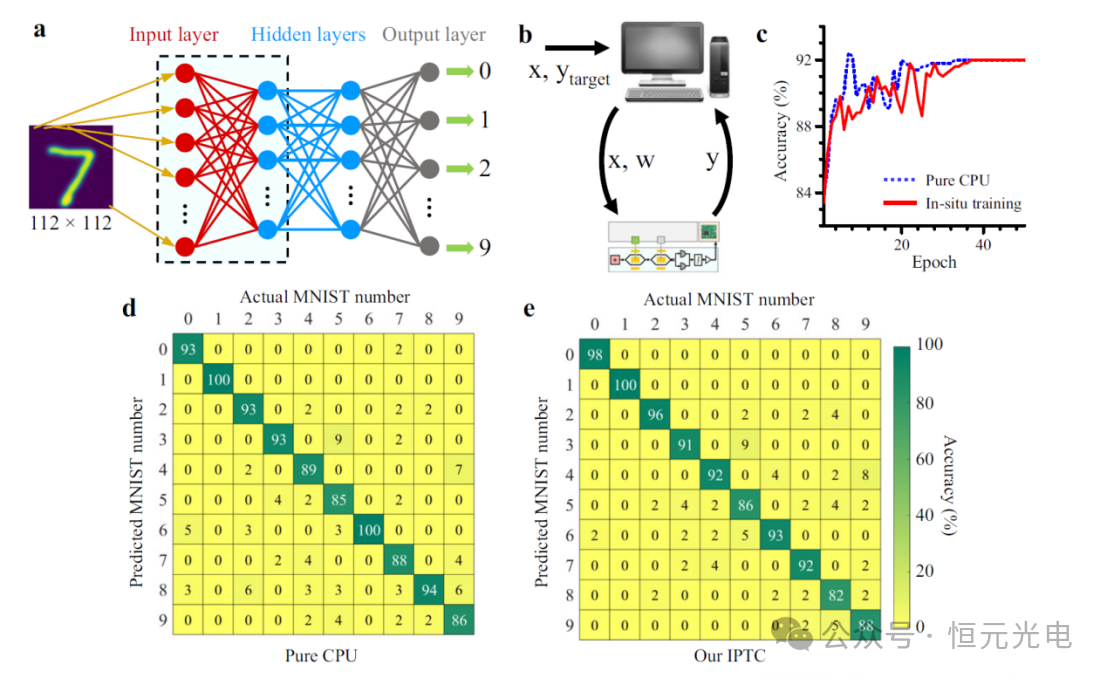
图4 设备对手写数字进行分类的结果。a多层感知器神经网络的框图。b现场训练示意图。c与仅在中央处理单元(CPU,蓝色虚线)上运行的方案相比,现场训练(实线)方案的验证精度随时间变化。d、 e使用大规模数据库从理论上计算混淆矩阵和实验混淆矩阵。
分类是一项监督学习AI任务,需要标记数据来训练模型。该团队构建的多层感知器模型使用IPTC执行前向传播的原位训练方案(见图4b)用2000个标记的数字图像进行训练。同时,电子计算机处理非线性函数和反向传播。权重向量通过随机梯度下降法进行更新,允许迭代训练单个样本。重复从前向传播到反向传播的训练过程,直到收敛。图4c显示了与仅在中央处理单元(CPU)上运行相比,现场训练方案的验证精度随时间的变化。
500幅图像的混淆矩阵(图4d,e)显示,生成的预测准确率为91.8%,而CPU计算的数值结果准确率为92%。该团队所设计的IPTC达到了接近理论的精度,表明原位训练方案使系统能够固有地考虑硬件的非理想性,包括制造变化和噪声。
图像聚类
监督学习可以成功地解决现实世界的挑战,但它也有一些缺点。主要局限之一是,它需要大量准确标记的数据来训练模型。创建这样一个数据库是一项耗时且资源密集的任务,可能并不总是可行的。相比之下,无监督学习可以对未标记的数据进行操作,以发现其底层结构,为提取数据特征提供了一种替代方法。
该团队通过利用主成分分析对大规模手写数字进行聚类,展示了该团队研发设备在无监督学习AI任务中的潜力,主成分分析是最常用的无监督学习模型之一。主成分分析通过将高维数据几何投影到有限数量的主成分(PC)上,以获得数据的最佳摘要,从而简化了高维数据。该团对发研发设备的收敛速度与CPU的收敛速度相当(见图5b)。
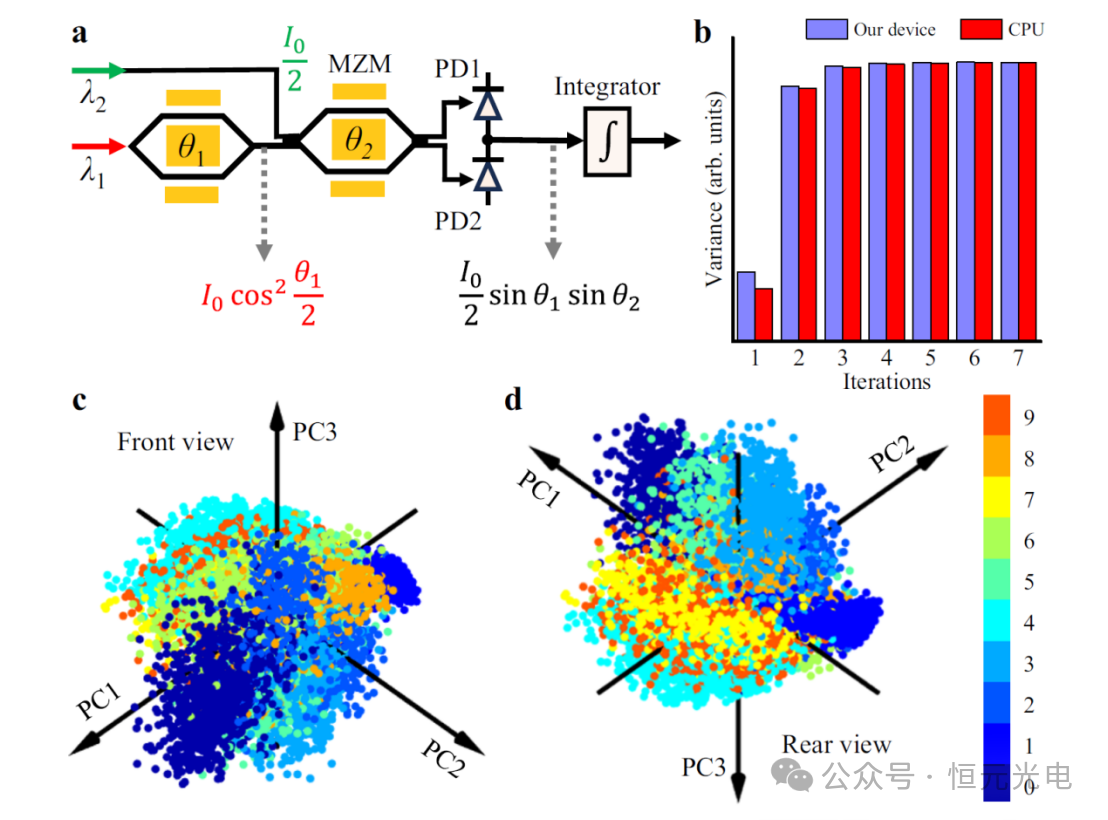
图5 使用设备对手写数字进行聚类的结果。a设备工作原理示意图。c、 d分别是基于投影到前三个主部件(PC)上的分数的每个手写指针的3D坐标的前视图和后视图。
此外,为了使用设备可视化手写数字的聚类结果,图5c和d显示了PC1-PC3上的投影,占特征的28.7%。尽管只使用了前三台PC,但未标记的手写数字仍然可以很好地聚类。
此外,该团队为了展示解决方案的可扩展性,提出了一种端到端的光子神经网络,该网络结合了TDM和WDM方法的优点,如图6所示。该网络能够同时执行多个AI任务,从输入层到输出层,延迟为纳秒,所有这些都不依赖于数字处理器的帮助。

图6 一个光子神经网络的示意图,旨在显示所提出的集成光子张量核心的可扩展性,该网络采用时分复用(TDM)和波分复用(WDM)相结合的混合方法。
总之,该团队已经通过实验证明,研发的IPTC可以执行大规模的矩阵向量乘法,具有灵活可调的扇入和扇出尺寸,并有助于快速更新权重。此IPTC具有处理两个负数之间乘法能力的开创性,能够通过现场训练处理监督和无监督学习AI任务。
我们身处于一个数据、信息量爆炸性增长的时代,一个由人工智能(AI)引领的、更加智能的时代。但是,持续增加的数据量在为 AI 提供源源不断的“动力”的同时,也对用于 AI 的电子计算硬件提出了更多的挑战,无论是在计算速度,还是在功耗方面,都已经成为严重制约 AI 发展的主要瓶颈之一。随着 AI 的兴起,传统的电子计算方法逐渐达到了其性能极限,并且滞后于可处理数据的快速增长。在各种类型的 AI 系统中,人工神经网络由于优异的性能而被广泛应用于 AI 任务,这些网络使用多层相互连接的人工神经网络进行复杂的数学运算。为了加速人工神经网络的处理,人们已经做出了各种努力来设计和实现特定的计算系统,通过将电子电路和数千或数百万个光子处理器集成到一个合适的架构中,一种同时利用光子和电子处理器的混合光电框架,或许在不久的将来可以彻底改变 AI 硬件。未来,这种硬件将在通信、数据中心营运和云计算等领域具有十分重要的应用。
本文地址:http://www.iccsz.com//Site/CN/News/2024/11/06/20241106110723218660.htm 转载请保留文章出处
关键字:
文章标题:用于推理和原位训练的薄膜铌酸锂中的120GOPS光子张量核心
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- · HyperLight获3700万美元B轮融资 加速TFLN PIC开发
- · 科学家构建基于薄膜铌酸锂的耦合微腔平台 助推未来光电融合芯片发展
- · 南智光电&逍遥科技:薄膜铌酸锂PDK应用线上研讨会
- · 华工科技:1.6T-200G/L高速硅光模块方案兼容薄膜铌酸锂调制器
- · 苏州易缆微发布创新性异质集成平台HISP® 助力铌酸锂产业升级
- · LC:2029年全球硅光子芯片市场将达30亿美元
- · 技术论文:数据中心光模块技术及演进
- · 南智光电薄膜铌酸锂光子芯片产线正式启动
- · OFC 2024专访|光库科技联合主办薄膜铌酸锂产业论坛 助推商业化进程
- · 光库科技携手HyperLight联合主办薄膜铌酸锂论坛
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1