LC:人工智能毫无悬念主宰了2024年Hot Chips大会
ICC讯 今年的年度Hot Chips会议代表了生成式人工智能(AI)炒作周期的顶峰。符合这一主题,OpenAI的Trevor Cai在他的主旨演讲中强调了AI计算的重要性。然而,在一个以技术披露闻名的会议上,商用芯片供应商的展示令人失望;尽管有一系列精彩的演讲,但几乎没有新的细节浮出水面。英伟达关于Blackwell的演讲大多重复了之前公布的信息。不过,在“一张图片胜过千言万语”的时刻,一张幻灯片上展示了下面所示的GB200 NVL36机架的照片。
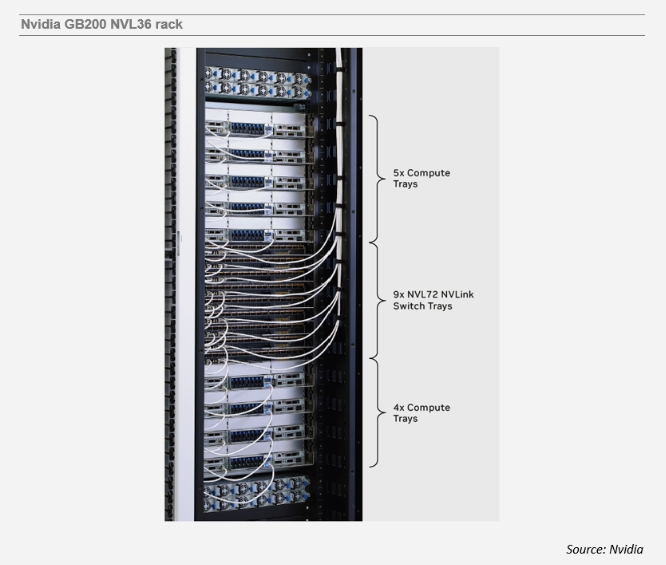
许多客户更偏爱耗电较少的NVL36配置,而不是需要巨大电力支持(每机架120千瓦)的NVL72配置。对于读者来说,关键的区别在于,机架中间显示的NVLink交换托盘具有前面板笼子,而用于NVL72的“不可扩展”NVLink交换托盘只有用于NVLink脊/背板的后面板连接器。尽管英伟达省略了布线细节,但外部NVLink线缆可能包括无源(DAC)和有源铜(ACC/AEC)以及可插拔光学器件。NVL36为布线创造了一个新的市场细分,尽管短期内主要针对铜缆。
英特尔早在今年四月份就宣布了其Gaudi 3 AI加速器,但重温一下它的网络规格还是值得的。新芯片集成了24个200G以太网端口,使用48个112G SerDes。像微软的Maia一样,Gaudi 3芯片可以直接连接以进行扩展,并通过交换机进行集群扩展。集成网卡支持RoCE协议,实现低延迟RDMA数据传输。在另一个演讲中,英特尔再次讨论了4Tbps光计算互连(OCI)芯粒。演讲者强调了激光集成的价值,并指出迄今为止已发货的超过3000万个激光器所展现的0.1FIT可靠性。
博通展示了其适用于带光接口的人工智能计算ASIC的共封装光学(CPO)技术。虽然演讲的第一部分主要介绍了Bailly CPO交换机,但后半部分包含了一些有关XPU的CPO的新细节和概念。公司引入了“Oceanfront”这个概念,它不同于硅Beachfront。将光学引擎附着到CoWoS封装基板上,为CPO提供了比硅中介层更多的线性空间。演讲还提出了在未来光学引擎中使用双向(bidi)信号的概念,以将所需的光纤数量减少一半。
也许商用芯片供应商在今年让位于数据中心运营商是合适的。毕竟,后者正在推动对AI基础设施的大规模投资。AI架构的多样性应该有利于供应链,在英伟达定制的全栈解决方案之外创造机会。
本文地址:http://www.iccsz.com//Site/CN/News/2024/09/05/20240905005011451818.htm 转载请保留文章出处
关键字:
文章标题:LC:人工智能毫无悬念主宰了2024年Hot Chips大会
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1