报告解读 | 光I/O+OCS引领智算中心Scale-Up网络架构新变革
ICC讯 在AI大模型加速演进的时代,智算中心光互联正经历从“横向扩展”(Scale-Out)向“纵向扩展”(Scale-Up)拓展的大变革。面对日益严苛的带宽、功耗与时延等挑战,6月5日,凌云光光纤器件与仪器事业部CTO 张华博士于OptiNet China 2025“智算中心光网络论坛”发表《面向智算中心Scale-Up网络光互联探讨》专题报告,深度解析光I/O与OCS协同构建可重构数据中心网络(RDCN)的关键趋势与技术方案,并分享了基于DBS技术的高可靠性OCS方案的最新进展。

AI时代光互联需求瓶颈,“四重挑战”呼唤架构革新
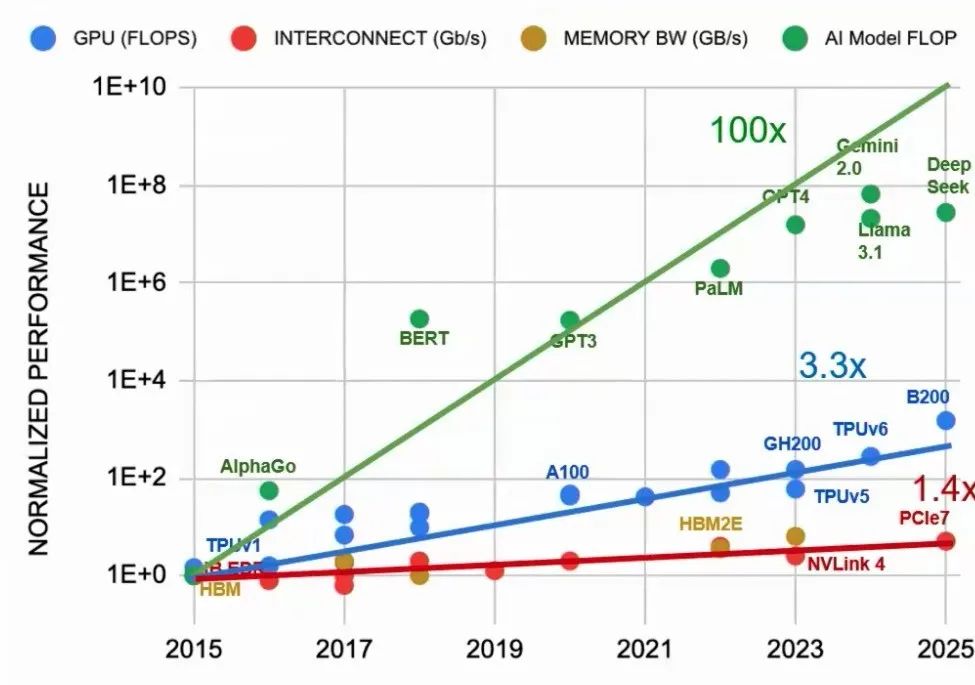
随着大模型参数规模呈指数级增长,智算中心正面临前所未有的网络瓶颈。张华博士指出,以ChatGPT为例,其参数量预计达到17万亿。与此同时,GPU算力每两年增长约3.3倍,而网络互联与存储带宽的增幅仅为1.4倍,形成明显“剪刀差”。这一不平衡的发展使得网络架构正成为AI算力释放的关键制约因素,也预示着未来在底层互联技术上存在巨大的优化空间,而智算中心网络正面临着“两高两低”的核心挑战:① 高带宽:大模型训练涉及大量GPU间的数据交互和周期性存储,单卡互联带宽需求可达14.4Tbps。② 高可靠:训练周期通常以周甚至月为单位,网络系统需保持持续稳定运行,任何中断都可能导致训练失败或算力资源浪费。③ 低功耗:光模块功耗占设备整体功耗已高达1/3,随着接口速率与数量增长,控制互联系统能耗成为系统设计的重要挑战。④ 低时延:多GPU协同计算对时延极为敏感,任何微小延迟都会引发等待与算力浪费。研究显示,每增加10μs时延,GPU利用率将下降1%至3%。
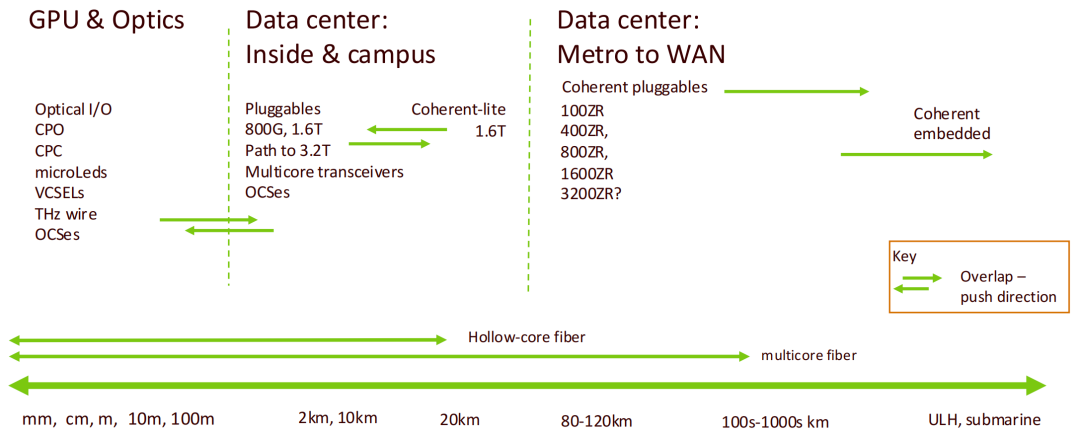
从实际应用层级看,当前光互联技术主要可分为三类核心场景:短距互联:应用于数据中心内部的Scale-Out与Scale-Up架构之间,如光I/O、CPO、800G/1.6T可插拔模块、LRO等。中长距互联:如数据中心之间的DCI互联,采用ZR/ZR+等相干光模块。超长距传输:如跨区域骨干网及海底光缆系统,保障全球算力网络的高效协同。
面对上述挑战,传统以铜缆电互联和电交换架构为主的短距互联也已逐渐力不从心,智算中心光互联正在呈现Scale-Out与Scale-Up双向发展的架构趋势,光互联正成为突破算力互联瓶颈、构建高效智算中心网络的关键路径。光互联从Scale-Out向Scale-Up拓展打造智算中心“超级节点”
当前主流智算中心多采用Scale-Out架构,通过网卡与交换机连接多个计算节点,适用于数据并行/流水线并行的相对低带宽和时延不敏感的集合通信。但随着训练/推理任务规模扩大,张量并行和专家并行这些对高带宽和低时延要求更高的集合通信,只有Scale-Up网络能够满足,但要求Scale-Up网络规模从8卡向百卡乃至千卡扩展,电互联架构已严重制约卡间协同效率,日益成为性能瓶颈。
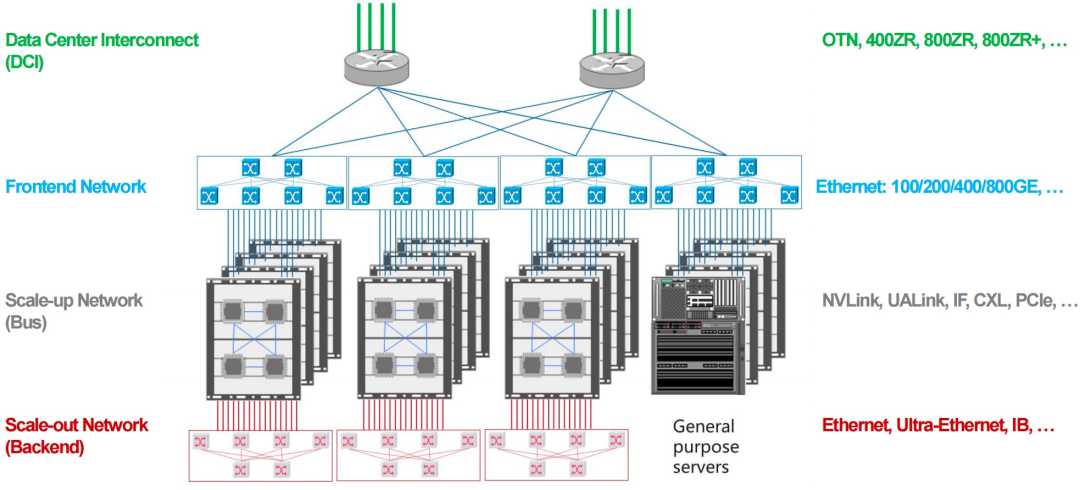
张华博士指出,Scale-Up架构强调在物理层面将多块GPU/XPU进行高密度直连,更好地匹配大模型对强耦合计算的需求。在此趋势下,光I/O技术的引入突破了传统电互联在带宽、时延与传输距离方面的限制,成为支撑Scale-Up架构的关键技术。相比铜缆,光I/O具备更大的带宽密度和更低的能耗,很容易实现跨机柜的GPU稳定互联。具体来看,光I/O赋能的Scale-Up网络有以下显著优势:超大规模:GPU卡间传输距离可达上百米,支持Scale-Up网络扩展至百卡乃至千卡级超节点。超高带宽:单GPU节点可实现高达256Tbps的双向互联带宽,是传统电互联架构的数十倍。超低时延:端到端传输时延可压缩至百纳秒级,显著提升GPU协同计算效率。
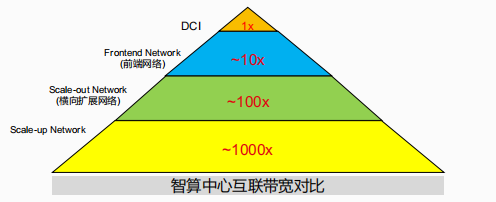
此外,OCS(全光交换)技术的引入,为Scale-Up架构提供了物理层的拓扑重构能力。通过光层级联、动态切换与信号透明传输,OCS与光I/O的协同组合构建出可重构数据中心网络(RDCN),为未来AI集群提供更高性能、更低能耗与更强弹性的新一代互联底座。光I/O技术突破铜缆瓶颈加速走向规模部署
在支撑AI大模型训练的算力架构演进中,光I/O作为高密度、低功耗、低时延的关键互联技术,正逐步替代传统电互联,成为构建Scale-Up网络“超级节点”的核心方案。尤其在铜缆在带宽、能耗与传输距离上的局限日益凸显的背景下,光I/O的技术落地与产业化进展,正在推动AI基础设施完成从“铜”到“光”的关键跨越。报告中介绍了多家领先厂商在光I/O技术上取得突破性进展:Ayar Labs推出业界首款符合UCIe规范的光子互联芯粒TeraPHY,采用微环调制技术,可实现高达8.192Tbps的双向带宽,并已在富士通 A64FX 处理器上实现原生光口部署。Lightmatter在OFC 2025发布Passage L200光引擎,采用波分与空分复用架构,单芯片带宽高达56Tbps,具备3D封装与堆叠能力,定位于大规模AI集群的高密度部署。Avicena则以microLED技术实现6.4Tbps级光连接,具备低功耗、高可靠、耐高温等优势,且兼容CMOS工艺,展现出极强的工程化潜力。这些技术路线的并行推进,标志着光I/O从实验室走向量产部署的关键拐点已至。
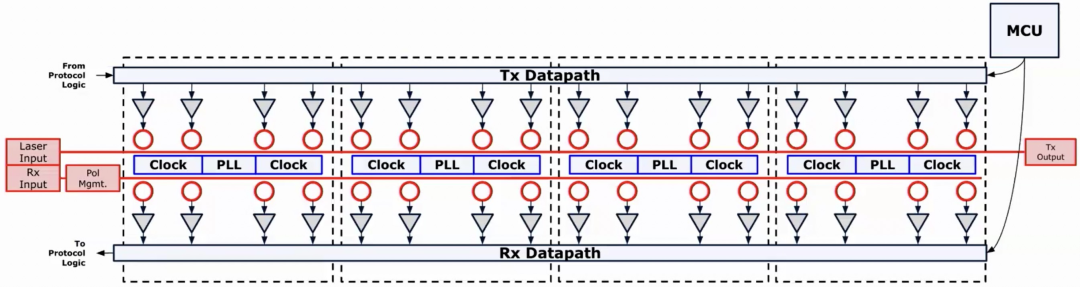
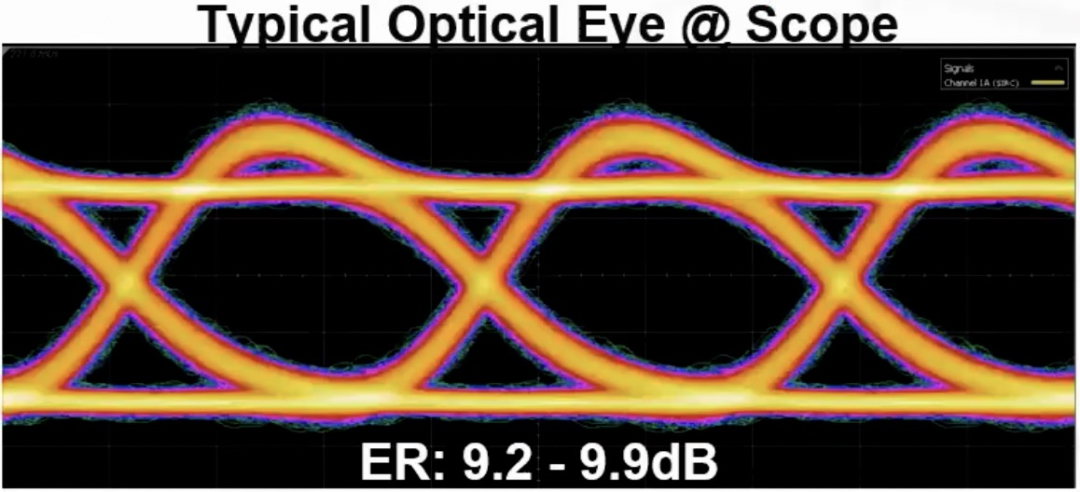
全光交换OCS技术赋能灵活拓扑与系统弹性
在传统数据中心中,网络拓扑通常为静态结构,适配稳定的流量模式。然而,AI训练任务具有突发性强、流量分布时空不均等特点,尤其在大模型并行计算中,不同阶段对带宽和拓扑需求差异显著。这就要求底层网络具备快速重构能力,以适应多任务切换与资源调度的灵活性。张华博士在报告中指出,全光交换(OCS,Optical Circuit Switch)技术,正是应对这一挑战的关键手段。相比传统电交换,OCS通过纯光信号直接切换物理链路,无需进行电光转换,具备高带宽、低时延、低功耗与协议无关等优势,可在毫秒级完成拓扑调整或故障切换,显著提升网络稳定性与弹性。在AI训练集群中,OCS可根据模型结构与计算负载动态调整互联结构,从而实现算力资源的最优利用。
报告指出,OCS在当前智算中心中的应用正逐步走向成熟,典型代表如Google谷歌23年发表论文提到的TPU v4集群已全面落地基于OCS+光模块的3D Torus网络架构。该系统采用136×136端口OCS配合800G可插拔光模块,实现4096张TPU的灵活互联,并在以下维度上实现显著突破:性能提升:可灵活重构物理拓扑,匹配不同模型通信模式,整体训练性能最高提升 3.3倍;系统可靠性增强:在主机可靠性仅99%的条件下,系统仍能保持75%的算力吞吐能力。
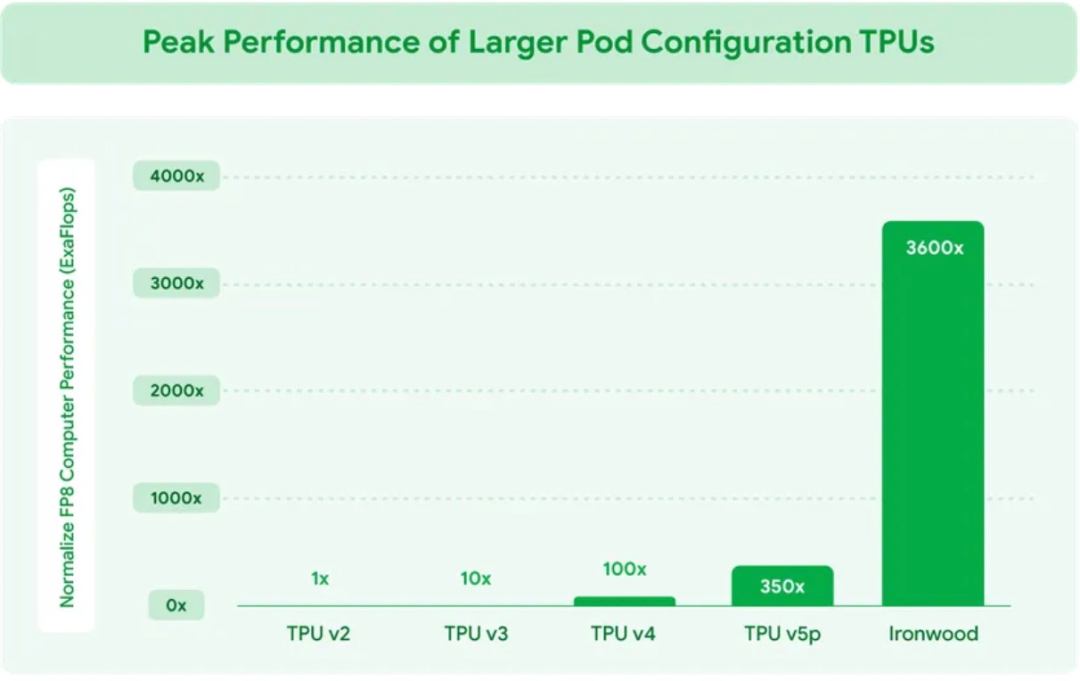
此外,Google谷歌在2025年Cloud Next大会上,宣布了最新智算集群Ironwood进展,已实现支撑9216张TPU卡间互联,同样基于OCS+800G光模块方案,相比TPUv2,计算性能提升3600倍,展现出OCS在AI集群架构中的广阔前景。可重构数据中心网络(RDCN)光互联光I/O + OCS协同构建“光速核心”
面对AI大模型训练对带宽密度、资源调度与系统弹性的极致要求,报告提出以光I/O与OCS技术为核心,构建可重构数据中心网络(RDCN)架构,实现物理层的灵活互联与资源解耦。RDCN架构融合了横向扩展的Scale-Out网络与纵向扩展的Scale-Up网络,通过OCS核心交换节点与GPU光I/O直连,实现从芯片到系统的全光互联。以哥伦比亚大学提出的SiPAM硅光互连架构为例,OCS+OIO组合在训练效率上相较传统Nvlink平台提升高达7.5倍,充分验证了全光互联在AI集群中的性能潜力。
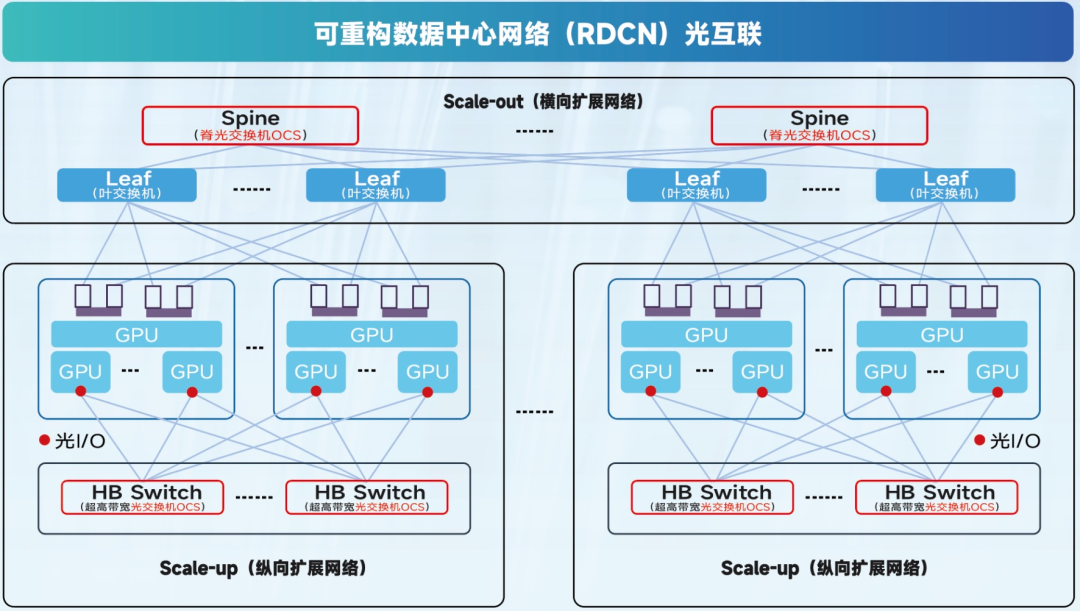
凌云光高可靠性OCS方案赋能RDCN落地部署
在RDCN架构所需的大规模光交换领域,凌云光与HUBER+SUHNER POLATIS合作,提出基于DBS(DirectLight Beam Steering)技术的高可靠OCS方案展现出显著优势。相比传统MEMS架构,DBS方案采用压电陶瓷驱动准直器旋转,实现空间直耦精确对准,具备更高可靠性、更优回波损耗、更低插损等特点,相比与高驱动电压的MEMS方案,DBS平台OCS在大端口数和长期工作稳定可靠性方面更具扩展潜力。随着OCS端口规模持续扩大,系统对交换模块的损耗及可靠性提出更高要求。正如Google谷歌在其论文《Mission Apollo: Landing Optical CircuitSwitching at Datacenter Scale》中指出,“相较于MEMS架构,基于压电陶瓷的光交换技术在插入和回波损耗方面具备天然优势,当MEMS方案在良率和可靠性上不易管理时,技术路线的选择也可能随之转变。”这一趋势也为DBS架构在下一代OCS系统中的广泛应用提供了有力印证。

凌云光OCS产品目前已支持最大576×576端口规模,典型插损仅2.7dB,回波损耗优于–50dB,并可灵活配置8×8起的多种矩阵规格。产品还具备暗光配置与双向通道(Bidi)等特性,可显著提升端口利用率和系统架构自由度,并且已通过Telcordia GR-63民用级、及MIL-STD-810G等严苛抗震与极端环境测试,该产品累计运行超 188亿端口小时,稳定性与工程化水平均处于业内领先。
聚焦光子集成与全光网络持续推动AI网络架构演进
随着大模型与智能算力持续纵深发展,传统电互联架构已难以满足智算中心复杂的互联需求。以硅基光电子集成为代表的光I/O技术,可支撑百卡乃至千卡Scale-Up网络规模,成为下一代智算中心纵向扩展的热点方案;光I/O+OCS全光交换实现物理拓扑的灵活重构,故障快速恢复、速率平滑升级,将成为RDCN(可重构数据中心网络)不可或缺的底层支撑技术。正如Google谷歌工程副总裁在OFC 2025上所言:“我们正在见证新网络架构的文艺复兴(What we are seeing is a new renaissance for new architectures!)”。凌云光以光I/O和OCS为突破口,深耕光子集成与全光网络领域,推动AI智算中心底层互联架构重塑。未来,凌云光将继续携手合作伙伴,围绕高密度、低功耗、智能调度等方向持续突破,加速迈向“光速核心”的智能互联新时代。
本文地址:http://www.iccsz.com//Site/CN/News/2025/06/10/20250610015019148149.htm 转载请保留文章出处
关键字:
文章标题:报告解读 | 光I/O+OCS引领智算中心Scale-Up网络架构新变革
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1