DeepSeek:请继续折射人类千年文明的星光吧

暴击美股
就在北京时间1月27日深夜,国产大模型公司深度求索(DeepSeek)凭一己之力掀翻美国科技股。
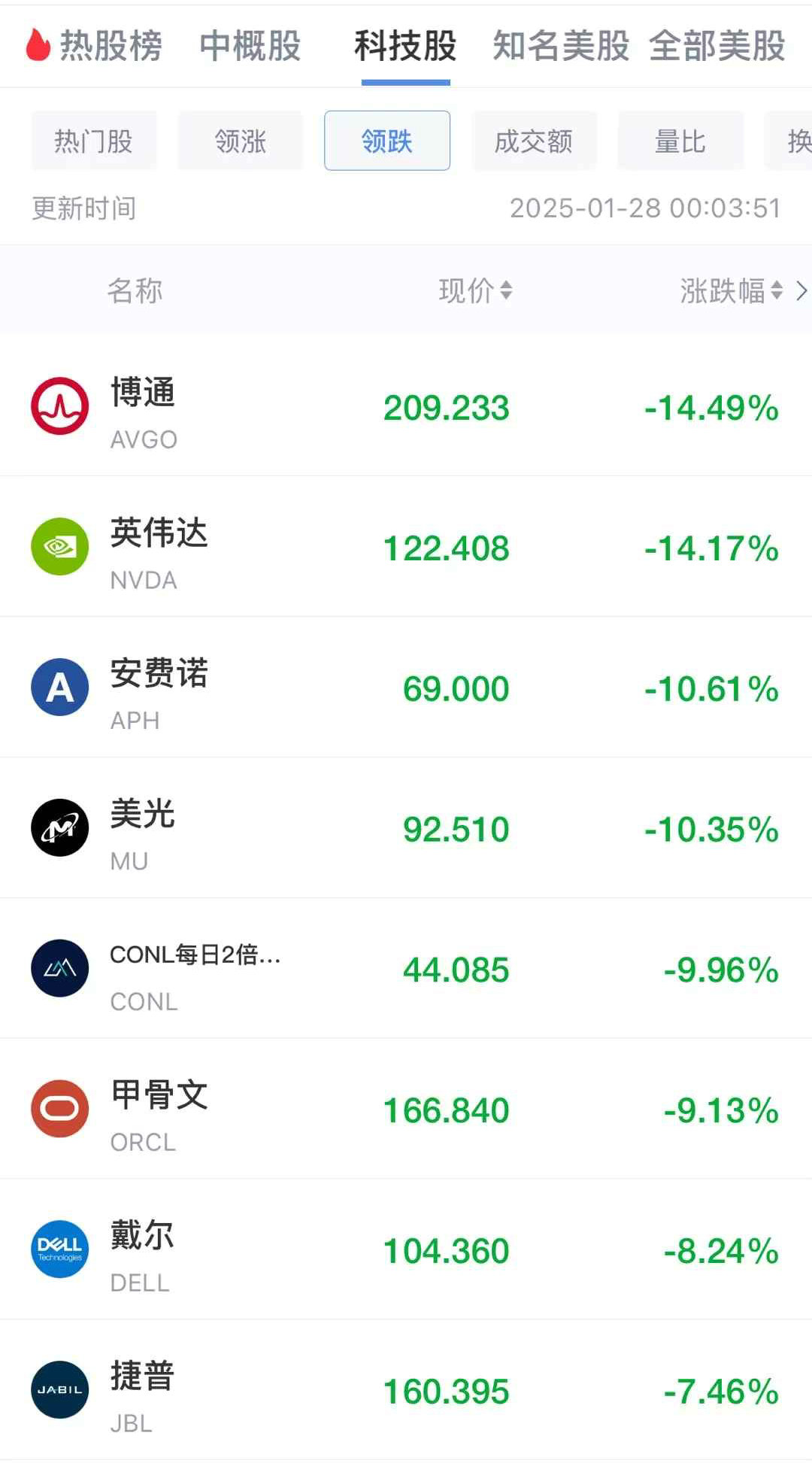
截至美股1月27日收盘,道指涨0.65%,标普500指数跌1.46%,纳指跌3.07%。英伟达暴跌16.97%,单日市值蒸发5890亿美元,创史上最大单日个股市值蒸发纪录。英伟达的暴跌也使得创始人黄仁勋的身家大幅缩水210亿美元。
此外,甲骨文下跌13.78%,超微电脑下跌12.49%,芯片制造商博通下跌17.4%,台积电跌13%。《华尔街日报》称,道琼斯市场数据显示,周一的“市场大屠杀”总共使股市市值蒸发了约1万亿美元。
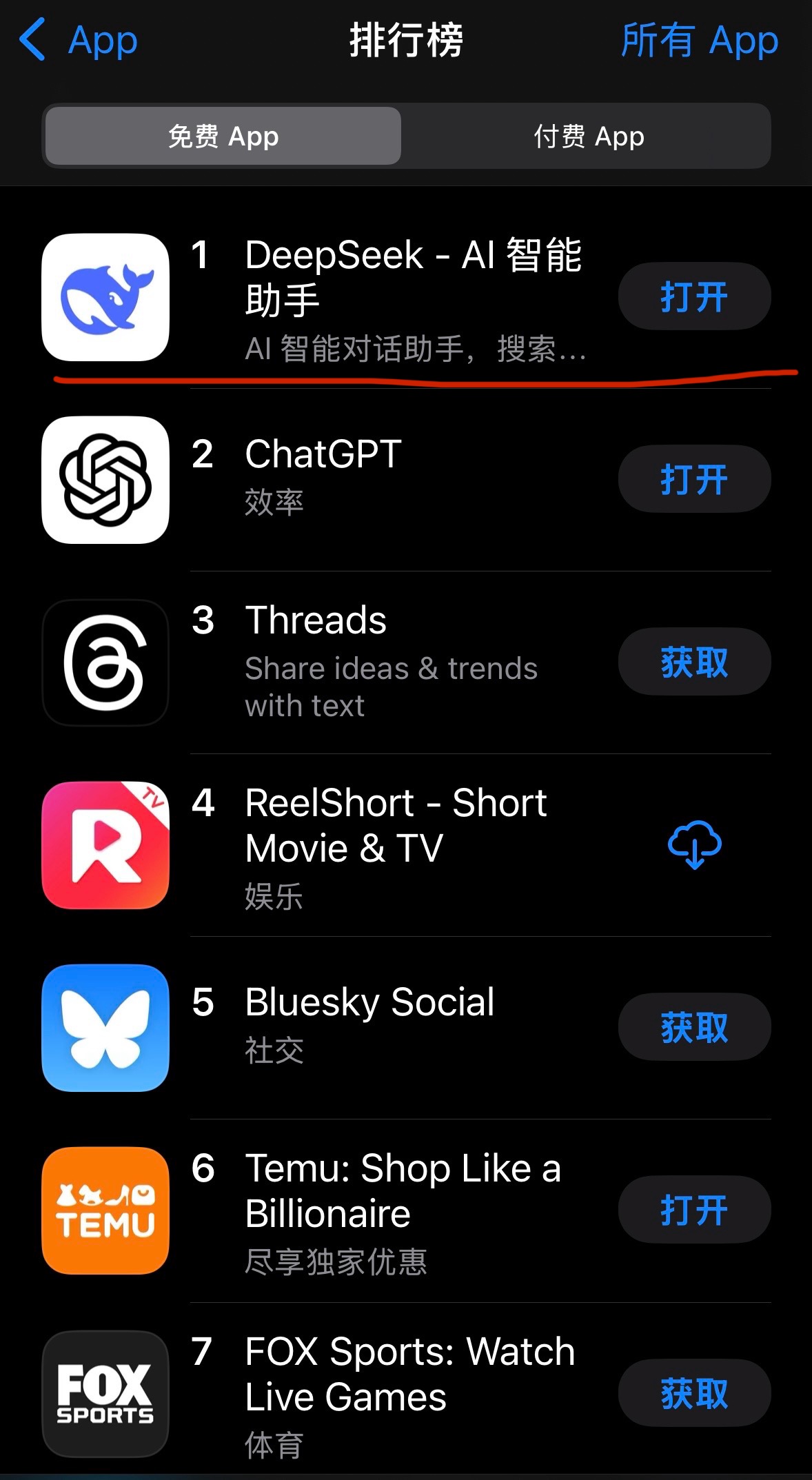
消息面上,1月27日早间,DeepSeek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上超越了ChatGPT。DeepSeek系量化巨头幻方量化旗下大模型公司,1月20日,该公司正式发布推理大模型DeepSeek-R1。
1月27日早间,DeepSeek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜,在美区下载榜上甚至超越了ChatGPT。DeepSeek是量化巨头幻方量化旗下大模型公司,1月20日,该公司正式发布推理大模型DeepSeek-R1。
推出后不久,R1就凭借其开源的性质、大幅下降的售价和训练成本获得了广泛关注。作为一款开源模型,R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAI o1模型正式版,并采用MIT许可协议,支持免费商用、任意修改和衍生开发等。
更令市场惊讶的是,据DeepSeek介绍,R1的预训练费用只有557.6万美元,在2048块英伟达H800 GPU(针对中国市场的低配版GPU)集群上运行55天完成。
市场人士称,DeepSeek的R1大型语言模型或引发行业重估大模型成本。华尔街开始考虑科技行业巨头对AI基础设施的巨额投资以及对英伟达芯片的需求是否合理。
值得注意的是,近日DeepSeek需求火爆,AI服务在24小时内经历了多次宕机。服务状态页面显示,“近期DeepSeek线上服务受到大规模恶意攻击,注册可能繁忙,请稍等重试。已注册用户可以正常登录,感谢理解和支持。”
暴击完美股,DeepSeek又抛出新模型。
1月28日,DeepSeek发布开源多模态模型Janus-Pro,其中70亿参数版本的Janus-Pro-7B模型在使用文本提示的图像生成排行榜中优于OpenAI的 DALL-E 3和Stability AI的Stable Diffusion。
Github社区信息显示,Janus-Pro是去年发布的Janus的高级版本,可显著提高多模式理解和视觉生成。相比此前的Janus,Janus-Pro优化的训练策略、扩展的训练数据和扩展到更大的模型尺寸。通过这些改进,Janus-Pro在多模态理解和文本到图像的指令遵循能力方面都取得了显著的进步,同时也增强了文本到图像生成的稳定性。
英伟达:DeepSeek未来仍需大量芯片
据路透社等外媒报道,当地时间27日,英伟达发表声明表示,中国人工智能公司深度求索(DeepSeek)所取得的进展,显示出其芯片在中国市场的实用价值,且未来为满足DeepSeek的服务需求,将需要更多英伟达芯片。
当地时间27日,因投资者担忧DeepSeek的英伟达芯片远少于美国公司,却达到了与OpenAI等竞争对手相当的水平,英伟达股价暴跌17%。之后,英伟达发布了一份声明。
英伟达在声明中称:“DeepSeek在人工智能领域取得了卓越进展,是‘测试时间缩放’的绝佳范例。DeepSeek的成果展示了如何利用这一技术,借助广泛可得的模型以及完全符合出口管制规定的计算资源,来创建新模型。”
英伟达还表示,DeepSeek等AI公司的推理需要大量英伟达GPU(图形处理器)和高性能网络,DeepSeek的爆火表明市场对其芯片仍有需求。
开源和闭源的冲突 对AI行业和英伟达都是短期利空长期利好
DeepSeek暴击美股的消息忙坏了中国网友,以下摘选一些犀利表达供参考:
当初openAI推出的时候,整个中国的科技界似乎都被震动了。悲观者感叹中国几十年也赶不上美国的人工智能,乐观者也觉得至少差那么三五年。
短短半年多以后,中国就推出了Deep SeekR1,用仅仅不到600万美元的成本实现了openAI几十亿美元才达到的性能和效率,更是打破了依靠先进芯片堆砌算力而垄断人工智能优势的梦想。
这可不是弯道超车啊,而是头顶飞跃。简直让人瞠目结舌,目瞪口呆!用不入流的芯片,只用了让觉得可怜得要命的资金就占领了人工智能的高地。
开源和闭源的冲突。正确的理解是开放源代码正在超越传统专有模式,但关于开源是否真的仅仅只是开放源代码这么简单,这部分暂时超出了我的认知,我不懂。但可以确定的是deepseek背后是接近50000台英伟达最先进A100芯片在支撑,而不是某些傻白甜想的对算力的需求大降,反而是随着使用的人数开始爆发式增长,面临着顶级算力不够的风险。但关于在美国技术封锁后这家公司为何依然能源源不断获得英伟达最先进的算力显卡,这部分无法明说,我只能说我认知之内的是,开源的投喂量和训练量是闭源是几十倍,开源想长期领跑,最好的显卡就是唯一的竞争。开源能长期获胜的关键是是否能一直拿到老黄的最新的芯片,中长期而言CUDA 无法替代。
两千年前中国人发明弩,普通农民稍加训练就可以洗脚上阵,战争不再是贵族的专利,直接导致中国贵族社会解体;又如这一年多战场上广泛应用的廉价无人机干掉昂贵传统兵器,小技术低价格往往能改变战争胜负的天平。
真正的仿大脑结构,就如人的记忆,需要的时候调出数据,不需要时就沉默在记忆深处。
DeepSeek团队刚在康奈尔发表的论文,其中每一个作者都值得我们铭记,大部分都是30岁以下的年轻人,来自国内的顶尖大学,有的还在读博士,其中,无人具有海外的学术背景。(也有网友表示“偷着乐闷头整就成了,为何非要去康奈尔发表?”)
用后反馈
关于DeepSeek的使用反馈,不少网友表示“比其他国产AI平台更好用。”

网友随机提问截图
但DeepSeek的使用仍需要细化问题,也就是你的提问必须要精准,它才能提供即时的详细答案。不过在提问了大宗商品相关后,如果参照它的答案,还是有可能掉坑的。它总结了一些谣言在里面作为分析结论。
但有个反之的问题,如果市场交易者应用这个模型做分析,形成共识,就会影响一段行情。然后分析师依靠AI写报告,AI再根据分析师报告做深度思考,提供结果,分析师再根据AI模型写报告.......
不管怎样,DeepSeek请继续折射人类千年文明的星光吧~
本文地址:http://www.iccsz.com//Site/CN/News/2025/01/28/20250128010516042819.htm 转载请保留文章出处
关键字:
文章标题:DeepSeek:请继续折射人类千年文明的星光吧
2、免责声明,凡本网注明“来源:XXX(非讯石光通讯网)”的作品,均为转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。因可能存在第三方转载无法确定原网地址,若作品内容、版权争议和其它问题,请联系本网,将第一时间删除。
联系方式:讯石光通讯网新闻中心 电话:0755-82960080-168 Right
- 设置首页 | 光通讯招聘 | 企业搜索库 | 广告服务 | 联系我们 | 保护私隐 | 公司介绍
Copyright ? 2009 ICCSZ.com Inc. All Rights Reserved. 讯石公司 www.iccsz.com版权所有 粤ICP备12008183号-1